
The Evolution of Language Models
Machine learning has made great strides in language models, which are essential for tasks like text generation and answering questions. Transformers and state-space models (SSMs) are key players, but they struggle with long sequences due to high memory and computational needs.
Challenges with Traditional Models
As sequence lengths grow, traditional transformers face quadratic complexity, making them inefficient. To tackle this, researchers have developed alternatives like Mamba, a state-space model that operates with linear complexity, enhancing scalability and efficiency for long-context tasks.
Cost and Resource Management
Large language models often incur high computational costs, especially when scaled to billions of parameters. Although Mamba is efficient, its size leads to increased energy consumption and training expenses. This is a challenge for models like GPT, which require full precision during training and inference.
Exploring Efficient Techniques
Researchers are investigating methods like pruning, low-bit quantization, and key-value cache optimizations to reduce these costs. Quantization helps compress models without losing much performance, but most studies focus on transformers, leaving a gap in understanding SSMs like Mamba under extreme quantization.
Introducing Bi-Mamba
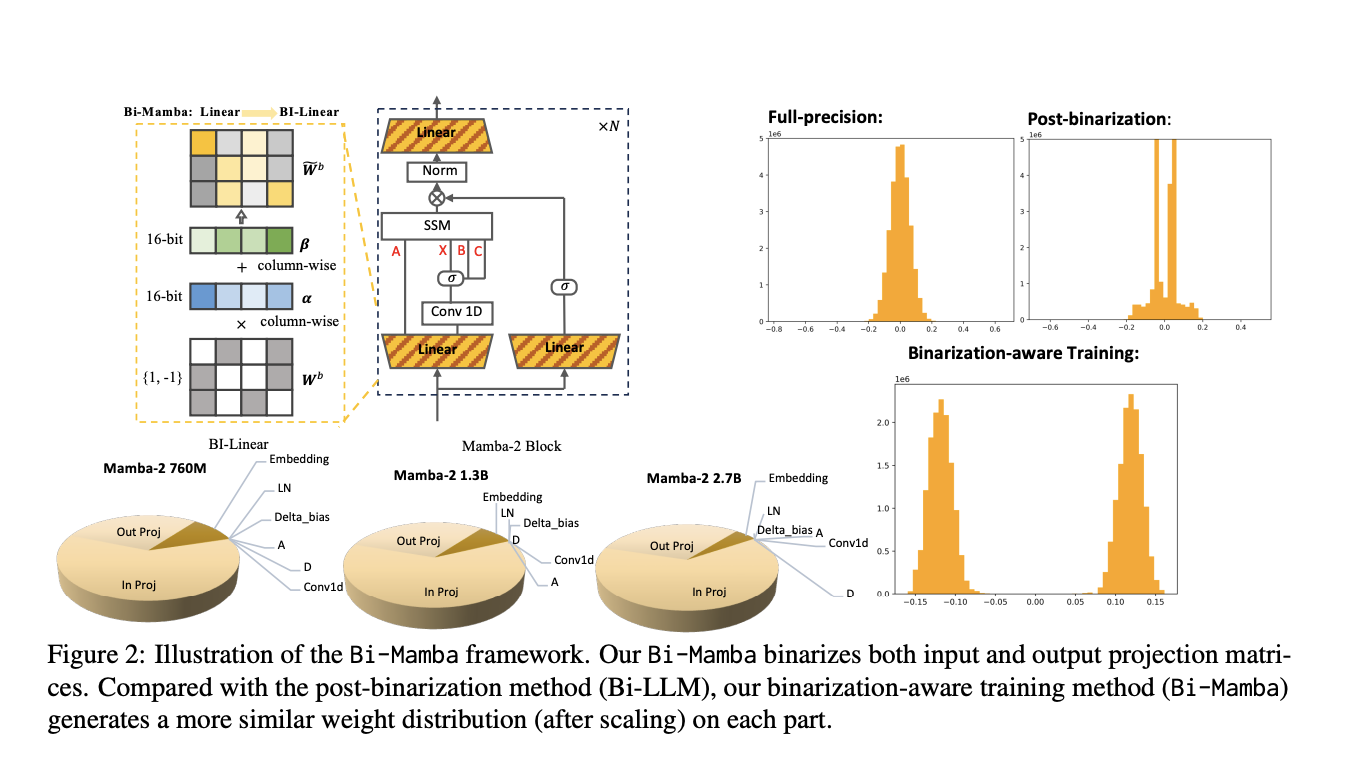
Researchers from Mohamed bin Zayed University of Artificial Intelligence and Carnegie Mellon University have created Bi-Mamba, a 1-bit scalable Mamba architecture designed for low-memory and high-efficiency applications. This model uses binarization-aware training to achieve extreme quantization while maintaining strong performance.
Key Features of Bi-Mamba
- Model Sizes: Available in 780 million, 1.3 billion, and 2.7 billion parameters.
- Training: Utilizes high-precision teacher models for effective training.
- Selective Binarization: Only certain components are binarized, balancing efficiency and performance.
Performance and Efficiency
Bi-Mamba has shown impressive results in various tests, achieving low perplexity scores and high accuracy on downstream tasks while significantly reducing storage size from 5.03GB to 0.55GB for the 2.7B model.
Key Takeaways
- Efficiency Gains: Over 80% storage compression compared to full-precision models.
- Performance Consistency: Comparable performance with much lower memory needs.
- Scalability: Effective training across different model sizes.
- Robustness: Maintains performance despite selective binarization.
Conclusion
Bi-Mamba is a significant advancement in making large language models more scalable and efficient. By using innovative training techniques and architectural optimizations, it shows that state-space models can perform well even under extreme quantization. This development enhances energy efficiency and reduces resource consumption, paving the way for practical applications in resource-limited environments.
Stay Connected
Check out the Paper for more details. Follow us on Twitter, join our Telegram Channel, and connect on LinkedIn. If you enjoy our work, subscribe to our newsletter and join our 55k+ ML SubReddit.
Upcoming Event
[FREE AI VIRTUAL CONFERENCE] Join us on Dec 11th for SmallCon, a free virtual GenAI conference featuring industry leaders. Learn how to build big with small models.
Transform Your Business with AI
To stay competitive, consider how AI can enhance your operations:
- Identify Automation Opportunities: Find customer interaction points that can benefit from AI.
- Define KPIs: Ensure measurable impacts from your AI initiatives.
- Select an AI Solution: Choose tools that fit your needs and allow for customization.
- Implement Gradually: Start with a pilot project, gather data, and expand wisely.
For AI KPI management advice, contact us at hello@itinai.com. For ongoing insights, follow us on Telegram or Twitter.
Discover how AI can transform your sales processes and customer engagement at itinai.com.
























