
Understanding Vision Transformers (ViTs)
Vision Transformers (ViTs) have changed the way we approach computer vision. They use a unique architecture that processes images through self-attention mechanisms instead of traditional convolutional layers found in Convolutional Neural Networks (CNNs). By breaking images into smaller patches and treating them as individual tokens, ViTs can efficiently handle large datasets, making them ideal for tasks like image classification and object detection.
Key Benefits of ViTs:
- Scalable processing for large datasets.
- Effective for high-dimensional tasks.
- Flexible framework for various computer vision challenges.
The Role of Pre-Training in ViTs
There is ongoing debate about the importance of pre-training for ViTs. While it has been believed that pre-training improves performance by learning useful features, recent research suggests that attention patterns might be just as crucial. Understanding these mechanisms could lead to better training methods and enhanced performance.
Challenges with Traditional Pre-Training:
- Difficulty in isolating contributions of attention and feature learning.
- Limited analysis of attention mechanisms impacts.
Introducing Attention Transfer
Researchers from Carnegie Mellon University and FAIR have developed a new method called Attention Transfer. This approach focuses on transferring only the attention patterns from pre-trained ViTs, using two techniques:
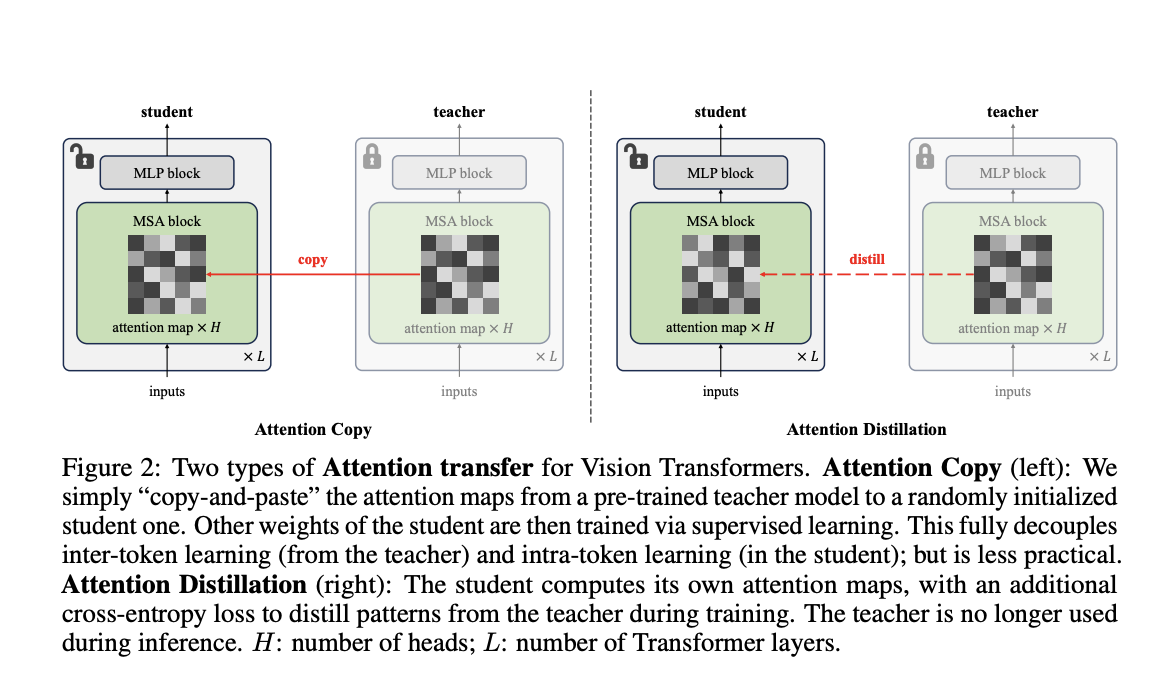
1. Attention Copy:
This method applies attention maps from a pre-trained model directly to a new model, allowing it to learn other parameters from scratch.
2. Attention Distillation:
This technique aligns the new model’s attention maps with those of the pre-trained model using a loss function, making it more practical as the pre-trained model is not needed after training.
Performance Insights
Both methods demonstrate the effectiveness of attention patterns:
- Attention Distillation: Achieved 85.7% accuracy on the ImageNet-1K dataset.
- Attention Copy: Reached 85.1% accuracy, closing the gap between training from scratch and fine-tuning.
- Combining both models improved accuracy to 86.3%.
Future Directions
This research indicates that pre-trained attention patterns can lead to high performance in downstream tasks, challenging traditional feature-centric training methods. The Attention Transfer method offers a new approach that minimizes reliance on heavy weight fine-tuning.
Next Steps:
- Address challenges like data distribution shifts.
- Refine attention transfer techniques.
- Explore applications across various domains.
Get Involved
For more insights and updates, follow us on Twitter, join our Telegram Channel, and connect with our LinkedIn Group. If you appreciate our work, subscribe to our newsletter and join our 55k+ ML SubReddit.
Join Our Free AI Virtual Conference
Don’t miss SmallCon on Dec 11th, featuring industry leaders like Meta, Mistral, and Salesforce. Learn how to build effectively with small models.
Transform Your Business with AI
Discover how AI can enhance your operations:
- Identify Automation Opportunities: Find key areas for AI integration.
- Define KPIs: Measure the impact of your AI initiatives.
- Select an AI Solution: Choose tools that fit your needs.
- Implement Gradually: Start small, gather data, and expand.
For AI KPI management advice, contact us at hello@itinai.com. Stay updated on AI insights via our Telegram or Twitter.
Explore more about redefining sales processes and customer engagement at itinai.com.

























