
Understanding Large Language Models (LLMs)
Large Language Models (LLMs) are powerful tools used in many applications. However, their use comes with challenges. One major issue is the quality of the training data, which can include harmful content like malicious code. This raises the need to ensure LLMs meet specific user needs and prevent misuse.
Current Solutions and Their Limitations
To tackle these challenges, methods like Reinforcement Learning from Human Feedback (RLHF) have been developed. RLHF tries to align LLM outputs with human preferences but has drawbacks, such as requiring a lot of computing power and being unstable. This highlights the need for better, more efficient ways to fine-tune LLMs while ensuring responsible AI development.
Emerging Solutions for Fine-Tuning LLMs
Several methods have been created to improve the alignment of LLMs with human preferences. RLHF was initially popular but is complex and resource-heavy. This led to the creation of Direct Policy Optimization (DPO), which simplifies the process by removing the need for a reward model and using a simpler loss function.
Introducing H-DPO
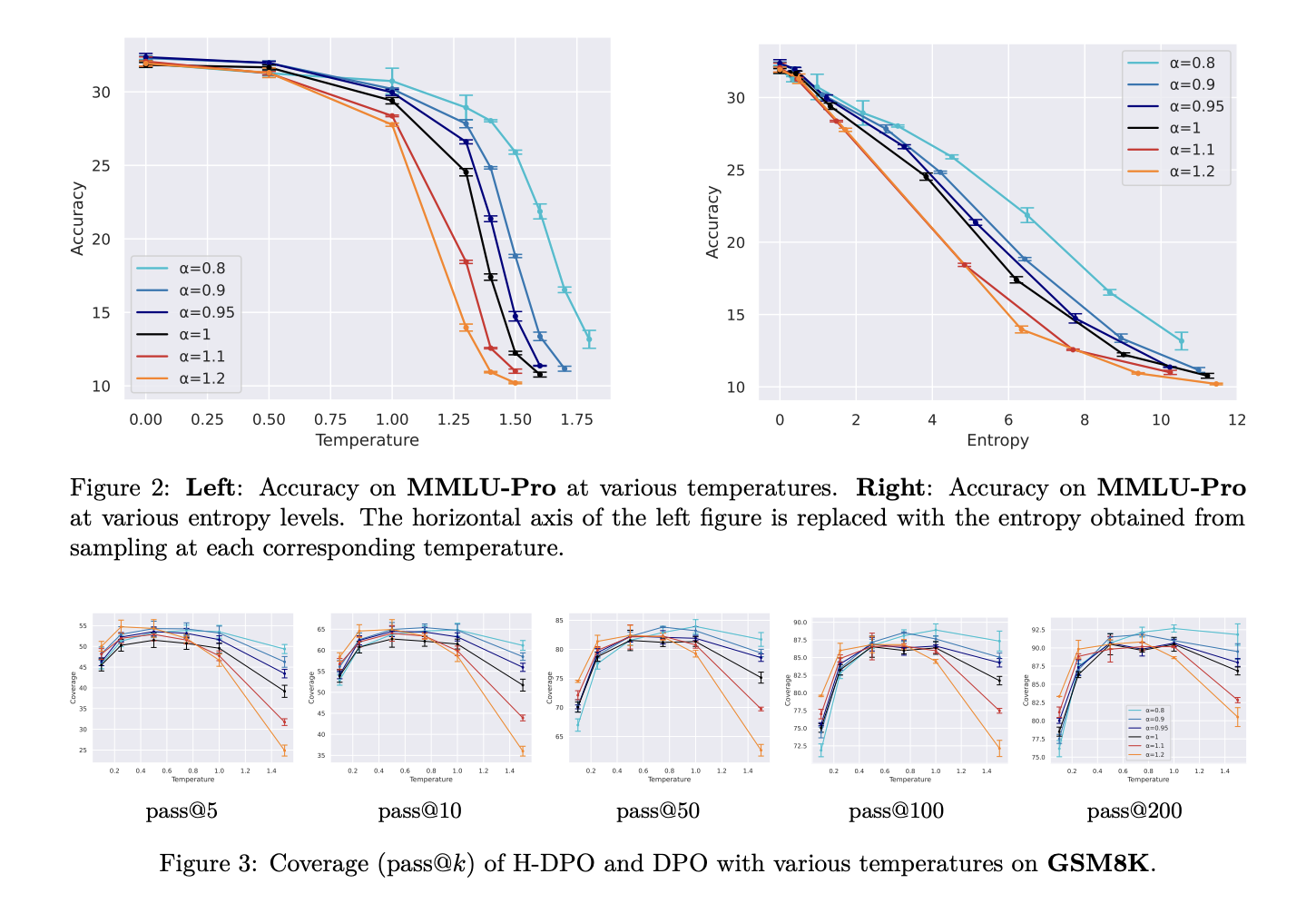
Researchers from The University of Tokyo and Preferred Networks, Inc. have developed H-DPO, an enhanced version of DPO. H-DPO improves upon DPO by better controlling the output distribution. It uses a hyperparameter α to adjust the entropy of the model, which helps in achieving better results when fitting complex data distributions.
Benefits of H-DPO
The H-DPO method allows for precise control over the model’s output by modifying the divergence term used in training. This leads to better performance in various tasks, including math problems and coding challenges. The implementation of H-DPO is straightforward, requiring minimal changes to existing systems.
Experimental Results
Tests show that H-DPO significantly outperforms standard DPO across various benchmarks. By adjusting the hyperparameter α, H-DPO can enhance performance in tasks like grade school math and coding, demonstrating its effectiveness in improving both accuracy and diversity of outputs.
Conclusion
H-DPO is a notable advancement in aligning language models, offering a simple yet powerful method to improve AI systems. Its ability to control output distribution effectively makes it a valuable tool for developing more accurate and reliable AI applications.
Get Involved
Check out the research paper for more details. Follow us on Twitter, join our Telegram Channel, and LinkedIn Group for updates. If you appreciate our work, subscribe to our newsletter and join our 55k+ ML SubReddit community.
Free AI Webinar
Join our upcoming webinar on implementing Intelligent Document Processing with GenAI in Financial Services and Real Estate Transactions.
Transform Your Business with AI
Stay competitive by leveraging H-DPO for your AI needs. Here’s how:
- Identify Automation Opportunities: Find key areas in customer interactions that can benefit from AI.
- Define KPIs: Ensure your AI projects have measurable impacts.
- Select an AI Solution: Choose tools that fit your needs and allow for customization.
- Implement Gradually: Start small, gather data, and expand wisely.
For AI KPI management advice, contact us at hello@itinai.com. Stay updated on AI insights via our Telegram and Twitter.
Explore AI Solutions
Discover how AI can enhance your sales processes and customer engagement at itinai.com.


























