
Evaluating the Real Impact of AI on Programmer Productivity
Understanding the Problem
The increasing use of large language models (LLMs) in coding presents a challenge: how to measure their actual effect on programmer productivity. Current methods, like static benchmarks, only check if the code is correct but miss how LLMs interact with humans during real coding tasks.
Why a New Evaluation Method is Needed
While many LLMs assist with programming, assessing their effectiveness often relies on outdated benchmarks. These don’t reflect how programmers work with LLMs in practice. Key factors like coding time, acceptance of suggestions, and problem-solving assistance are overlooked. This gap raises questions about the relevance of traditional evaluation methods.
Introducing RealHumanEval
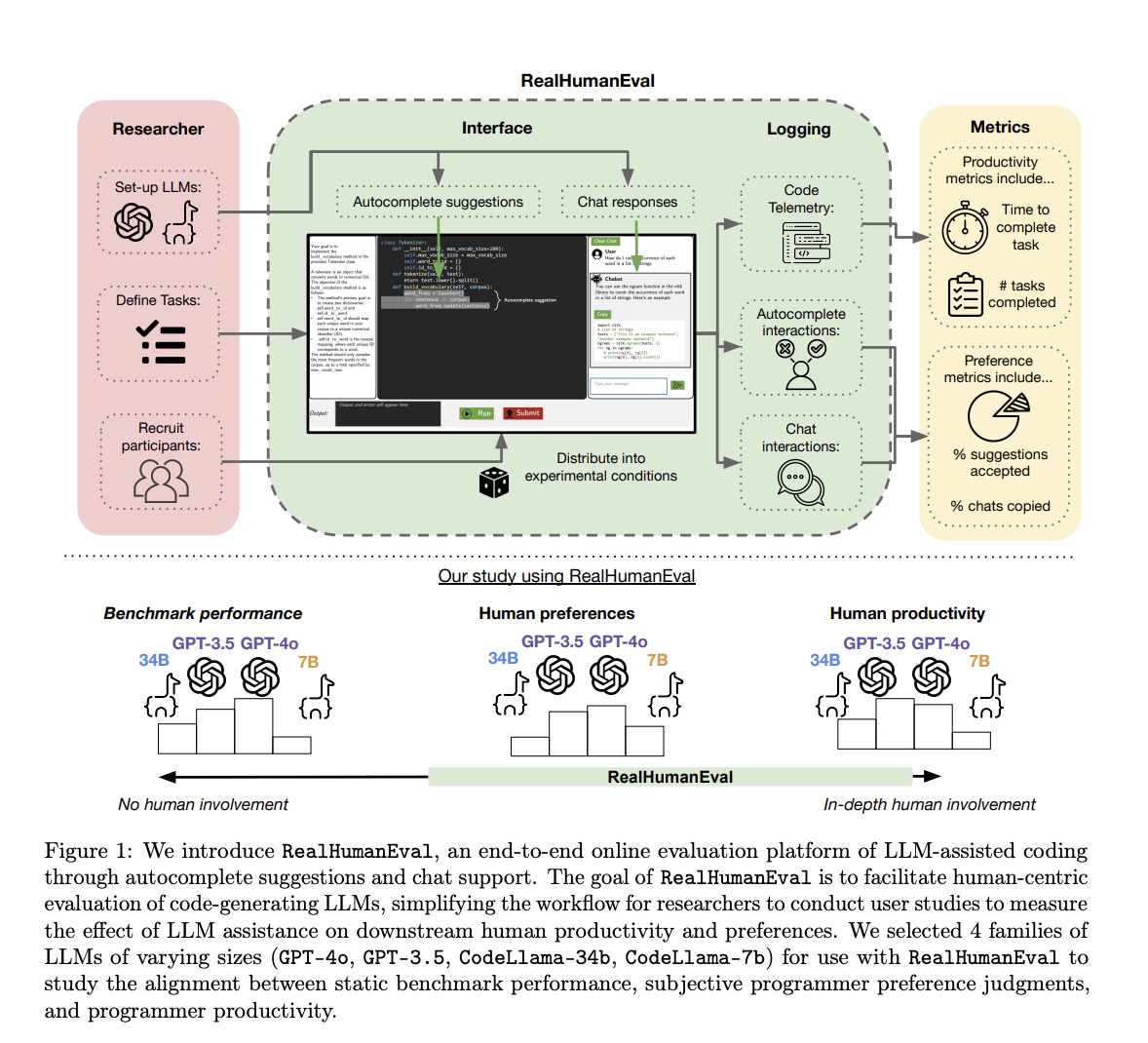
Researchers from various leading institutions created **RealHumanEval**, a new platform for assessing LLMs with a focus on human interactions. It allows real-time evaluation through two interaction modes: autocomplete suggestions and chat-based assistance. The platform tracks essential metrics like task completion time and suggestion acceptance, providing a clearer picture of how LLMs impact real-world coding.
How RealHumanEval Works
RealHumanEval tested seven different LLMs on 17 tasks of varying complexities. It logged performance details such as time spent and tasks completed during the testing involving 243 participants. This rigorous analysis helps clarify how LLMs can enhance efficiency in coding tasks.
Insights Gained
The testing revealed that higher-performing models like GPT-3.5 and CodeLlama-34b helped programmers finish tasks quicker — by 19% and 15%, respectively. However, not all models performed equally; for some, like CodeLlama-7b, the evidence of productivity improvements was less convincing. While LLMs could speed up task completion, they didn’t significantly increase the number of tasks finished within a specific timeframe.
Conclusion: A New Standard for Evaluation
**RealHumanEval** is groundbreaking because it prioritizes human-centered metrics rather than traditional benchmarks. It provides valuable insights into how LLMs assist real programmers, revealing both strengths and weaknesses of these tools in coding environments.
Get Involved
For more insights from this research, check out the detailed paper and follow us on social media platforms like Twitter, Telegram, and LinkedIn. Join our growing community and subscribe to our newsletter for updates.
Transform Your Business with AI Solutions
If you want to stay competitive and leverage AI effectively, explore how **RealHumanEval** can benefit your team. Recognize areas where AI can automate processes, define key performance indicators (KPIs), choose suitable AI tools, and implement solutions gradually.
For further assistance with AI strategy, contact us at hello@itinai.com and stay updated with our insights on Telegram and Twitter. Discover how AI can enhance your operations at itinai.com.






















